Lexicon organisation
Lexicon organisation
I assume not everyone here knows by heart all their conlangs' lexicons, so how do you keep records of them? Notebook, text editor, spreadsheets? What pieces of information do you put in each entry?
/j/ <j>
Ɂaləɂahina asəkipaɂə ileku omkiroro salka.
Loɂ ɂerleku asəɂulŋusikraɂə seləɂahina əɂətlahɂun əiŋɂiɂŋa.
Hərlaɂ. Hərlaɂ. Hərlaɂ. Hərlaɂ. Hərlaɂ. Hərlaɂ. Hərlaɂ.
Ɂaləɂahina asəkipaɂə ileku omkiroro salka.
Loɂ ɂerleku asəɂulŋusikraɂə seləɂahina əɂətlahɂun əiŋɂiɂŋa.
Hərlaɂ. Hərlaɂ. Hərlaɂ. Hərlaɂ. Hərlaɂ. Hərlaɂ. Hərlaɂ.
-
Curlyjimsam
- Posts: 98
- Joined: Mon Jul 30, 2018 8:21 am
Re: Lexicon organisation
After experimenting with various possibilites, I have found the best way for me is generally Excel spreadsheets. Sample of a typical entry:
igak | mod. | beautiful | COV igaks "sunny, bright"
(headword | part of speech | translation | etymology)
Other information (e.g. usage, irregular morphology) is placed in the "translation" column as necessary.
igak | mod. | beautiful | COV igaks "sunny, bright"
(headword | part of speech | translation | etymology)
Other information (e.g. usage, irregular morphology) is placed in the "translation" column as necessary.
The Man in the Blackened House, a conworld-based serialised web-novel.
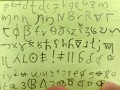
Re: Lexicon organisation
I put it in my grammar as the last section.
They are formatted like this:
apok абок [ˈä.bok] – in. stone, rock
(orthography (in this case two of them), phonetic transcription, definition)
The part of speech is usually clear to me. In this specific language, I write down whether a noun is animate or inanimate because it isn't always analysed as the animacy that seems most natural to me.
They are formatted like this:
apok абок [ˈä.bok] – in. stone, rock
(orthography (in this case two of them), phonetic transcription, definition)
The part of speech is usually clear to me. In this specific language, I write down whether a noun is animate or inanimate because it isn't always analysed as the animacy that seems most natural to me.
ìtsanso, God In The Mountain, may our names inspire the deepest feelings of fear in urkos and all his ilk, for we have saved another man from his lies! I welcome back to the feast hall kal, who will never gamble again! May the eleven gods bless him!
kårroť
kårroť
Re: Lexicon organisation
I use MS Excel. Each major language gets a sheet of its own, but the lesser languages share a pad and therefore have a lot of blank entries since not every language inherits every root. I tried using MS Access once, which would have allowed me to link cells to other cells and therefore keep track of cognates, but I found it too complicated so I regressed back to Excel. Both were free to me because at the time I was a student in a school offering training in basic computer proficiency.
I would discourage anyone from using paper if they can help it ... I started out that way in the 1990s and ended up losing most of my vocabulary just because my mother was cleaning and threw out most of the sheets. I have also thrown out some stuff on my own. But I've kept close watch on all my computer files.
In my Excel spreadsheets I include notes beside some entires that wouldn't matter to anyone browsing the dictionary, but help me keep track of things I might need to reconsider. For example, in Poswa, I have a word to "to cast a magic spell", and I wrote in the NOTES section cf "dedhu"~"desdu" since otherwise the etymology of this word would be a mystery to me, as it was homophonous with something else even 7000 years back in the history. But with "desdu" I can think, "Oh yeah, that has the word for spirit in it, ... I get it now". It helps me save words that otherwise would seem like mistakes.
I would discourage anyone from using paper if they can help it ... I started out that way in the 1990s and ended up losing most of my vocabulary just because my mother was cleaning and threw out most of the sheets. I have also thrown out some stuff on my own. But I've kept close watch on all my computer files.
In my Excel spreadsheets I include notes beside some entires that wouldn't matter to anyone browsing the dictionary, but help me keep track of things I might need to reconsider. For example, in Poswa, I have a word to "to cast a magic spell", and I wrote in the NOTES section cf "dedhu"~"desdu" since otherwise the etymology of this word would be a mystery to me, as it was homophonous with something else even 7000 years back in the history. But with "desdu" I can think, "Oh yeah, that has the word for spirit in it, ... I get it now". It helps me save words that otherwise would seem like mistakes.

Re: Lexicon organisation
This.
For Kala:

There are several other columns, but they are used for sorting and tracking purposes. Within the "POS/CAT" column, various identifiers are used to indicate whether the word has an Omyatloko glyph, if it is monosyllabic, has a corresponding affix, etc.
I also have many handwritten notebooks that I've used to update and track Kala over the years. Here's and example.
I've stopped using Excel for Amal and instead use Word exclusively, but it's still in its infancy, so that may well change.

-
Kuchigakatai
- Posts: 1307
- Joined: Mon Jul 09, 2018 4:19 pm
Re: Lexicon organisation
There was some good discussion about dictionary storage in this thread from a couple months ago:
http://verduria.org/viewtopic.php?f=3&t=139
http://verduria.org/viewtopic.php?f=3&t=139

Re: Lexicon organisation
With oligosynthetic language, I assume to know by heart all the lexicon...
But any speech tentative is a try to follow a precedent path or to find a new one...
with the risk, in a conversation on the fly, of losing my way, having to going back or to reach a wrong goal...
A sort of re-inventing of the wheel at each travel I do...
I could say all my lexicon is a map of engrams of precedent paths, or thoughts, more easy to find when they are more usual used, as any language, but without the tags of words...
But any speech tentative is a try to follow a precedent path or to find a new one...
with the risk, in a conversation on the fly, of losing my way, having to going back or to reach a wrong goal...
A sort of re-inventing of the wheel at each travel I do...
I could say all my lexicon is a map of engrams of precedent paths, or thoughts, more easy to find when they are more usual used, as any language, but without the tags of words...

Re: Lexicon organisation
Usually I use a spreadsheet but for Ngolu/Iliaqu I'm just using a text document. I can't remember why, but it's easy to search because I've developed a funny system, and it's easy to back-up and email to myself and whatever. Here's a sample:
Entries start with • and sub-entries with ◊ and use a tilda to represent the headword.
The double colon :: indicates the end of the headword. It means if I want to find an entry for a short word, for example, "za", I can simply type " za :" in the search box and leaving out the colon, simply having spaces on either side, will find not only the headword but any sub-headwords it's in as well as example sentences.
The part of speech is in (brackets).
If [square brackets] are there, it shows the rank that the word can apply to. This can be used after case abbreviations if it's not the nominative role that is restricted to rank.
Searchable keywords in translations are put within <angle brackets> which makes them easier to search for when, for example, I don't want to just find the words anywhere in the text, e.g. in explanations of a word.
For a lot of nominals, I don't include a translation but simply use a gloss because it would be too tedious and imprecise to include translations for all of them.
The letters within |pipes| in a translation are case abbreviations, which show the case assignment associated with verbs. I leave out Nominative if it's first in the translation and don't generally include ones that would be obvious, for example "at |L| associated with |G| owned by |P| because of |Ca| for the purpose of |B| ..." (those are Locative, Genitive, Possessive, Causative, Benefactive).
Further information is included in [square brackets] after the translation, including information about derivational processes that derived the word, such as "[from 'xuo' + 'maki']" and any references to other entries are put in 'single quotation marks' so I can search for any derivatives of a word by putting it in single quotation marks.
Words in {curly brackets} are further search tags for semantic domains, loanwords etc.
Example sentences following some entries, such as "za" above, are pretty self-explanatory, I think.Only that after the translation there is sometimes something to indicate the speech mode, e.g. [ICS/DOM] means the example could either be used in the inaccessible or dominant speech modes. Sometimes there is also an indication of which rank the example sentence comes from. Obviously the glosses only line up in a fixed-width font. The words in example sentences can all be searched by simply putting a space before and after.
I think that's about it. I keep finding little formatting errors here and there, but it's mostly pretty easy to use.
Code: Select all
• xui :: (n) ABL.3s.DEF.INAN <from it> <from the thing>
• xuiia :: (n) [contraction of 'xui' + 'tia']
• xuiie :: (n) [contraction of 'xui' + 'tie']
• xuiio :: (n) [contraction of 'xui' + 'tio']
• xuila :: (v) [KALI] is <sweet> <kind> <thoughtful> towards |D|
◊ ko ~ › (v) [MUJA] is <sweet> <kind> <thoughtful> towards |D|
• xume :: (v) is <necessary> to |D|; is <obligatory> for |D|; |D| <needs> <requires> |N| (≈ 'nase')
» Xume zuo ka loe nu jeu.
› xume zuo ka loe nu jeu
› necessary NOM.C PROS sleep NOM.1s.ICS same
› “I will need to sleep later too.” [ICS/DOM]
• xuo :: (v) is a <gap> <space> between |…|/|G| {spat}
◊ gixua ~ › (v) is <among> <amongst> |…|/|G| {loc}
◊ nxua ~ › (v) is <between> |…|/|G| {loc}
• xuomaki :: (v) is a <window> [from 'xuo' + 'maki']
• xuttia :: (v) <four> <and four> <plus four> [compounding form of number used as an addition rather than a multiplication, follows numbers of tens, from 'x-' + 'nuttia', see 'ava'] {quan}
• xuua :: (n) [contraction of 'xu' + 'tia']
• xuue :: (n) [contraction of 'xu' + 'tie']
• xuuo :: (n) [contraction of 'xu' + 'tio']
___________________________________________
Z z /z/
___________________________________________
• za :: (p) <that> <which> [uninflected particle introducing a relative clause which generally includes a resumptive pronoun]
» Iuxi va tiia za kue nu ixi to hueva xabas eni xu tie
› iuxi va tiia za kue nu ixi to hueva xaba ene xu tie
› GEN.3p.INAN.DEF all picture REL cause NOM.1s.ICS ACC.3p.INAN.DEF thus most happy.situation DAT.1s.ICS NOM.3s.INAN.DEF this1
› “Out of all of the pictures I've made, this one pleases me the most.” [ICS/DOM]
» Ha vu inju za ttu eni zuo nju vu?
› ha vu i- g- ju za ttu eni zuo g- ju vu
› Q NOM.2s.ICS PRED-COP-NOM.3s.ICS.DEF REL seem DAT.1s.ICS NOM.C COP-NOM.3s.ICS.DEF NOM.2s.ICS
› “Are you who I think you are?” [ICS]
» Kka nu inju za ttu eui zuo nju nu.
› kka nu i- g- ju za ttu eui zuo g- ju nu
› not NOM.1s.ICS PRED-COP-NOM.3s.ICS.DEF REL seem DAT.2s.MASC NOM.C COP-NOM.3s.ICS.DEF NOM.1s.ICS
› “I'm not who you think I am.” [ICS]
» Molas enio ixu eniovaru iza kka bo ixu ieri zua.
› mola enio ixu eniovaru i- za kka bo ixu ieri zua
› be.merely be.plant NOM.3P.DEF.INAN be.weed PRED-REL be.NEG be.wanted NOM.3P.DEF.INAN DAT.3P.NSPEC.ANIM LOC.3S.SPEC.INAN
› “Weeds are just plants that people don't want there.”
• zagua :: (v) is a <gibbon> {fau}
• zaha :: (v) [MUJA] <fights> <attacks> |A| for |T| because of |Ca| [physically, without weapons, cf. 'gazau'] {vio}
◊ le ~ › (v) is <violence>
• zaitia :: (v) is <guts> <entrails> <intestines> <internal organs> of |G| {bod}
• zaliu :: 1. is a <slug> <land slug> [shell-less land-living gastropod] {fau}
2. is <grease> <axle grease> [lubricant used to grease the axles of an 'ozuuo'] {Qu}
• zamita :: (v) is <Saturday> {loan} {DE} {Earth}
• zamu :: (v) <stands>
◊ ~ talu › (v) is <goosebumps>; |L|/|G| <has goosebumps>
• zara :: (v) <writes> |A| to |D| on |L|
◊ xo ~ :: (v) is a <scribe> <author> <writer> {job}
The double colon :: indicates the end of the headword. It means if I want to find an entry for a short word, for example, "za", I can simply type " za :" in the search box and leaving out the colon, simply having spaces on either side, will find not only the headword but any sub-headwords it's in as well as example sentences.
The part of speech is in (brackets).
If [square brackets] are there, it shows the rank that the word can apply to. This can be used after case abbreviations if it's not the nominative role that is restricted to rank.
Searchable keywords in translations are put within <angle brackets> which makes them easier to search for when, for example, I don't want to just find the words anywhere in the text, e.g. in explanations of a word.
For a lot of nominals, I don't include a translation but simply use a gloss because it would be too tedious and imprecise to include translations for all of them.
The letters within |pipes| in a translation are case abbreviations, which show the case assignment associated with verbs. I leave out Nominative if it's first in the translation and don't generally include ones that would be obvious, for example "at |L| associated with |G| owned by |P| because of |Ca| for the purpose of |B| ..." (those are Locative, Genitive, Possessive, Causative, Benefactive).
Further information is included in [square brackets] after the translation, including information about derivational processes that derived the word, such as "[from 'xuo' + 'maki']" and any references to other entries are put in 'single quotation marks' so I can search for any derivatives of a word by putting it in single quotation marks.
Words in {curly brackets} are further search tags for semantic domains, loanwords etc.
Example sentences following some entries, such as "za" above, are pretty self-explanatory, I think.Only that after the translation there is sometimes something to indicate the speech mode, e.g. [ICS/DOM] means the example could either be used in the inaccessible or dominant speech modes. Sometimes there is also an indication of which rank the example sentence comes from. Obviously the glosses only line up in a fixed-width font. The words in example sentences can all be searched by simply putting a space before and after.
I think that's about it. I keep finding little formatting errors here and there, but it's mostly pretty easy to use.
Glossing Abbreviations: COMP = comparative, C = complementiser, ACS / ICS = accessible / inaccessible, GDV = gerundive, SPEC / NSPC = (non-)specific, A/ₐ = agent, E/ₑ = entity (person or thing)
________
MY MUSIC | MY PLANTS | ILIAQU
________
MY MUSIC | MY PLANTS | ILIAQU
Re: Lexicon organisation
Your list reminds me a bit of http://www.lojban.org/publications/wordlists/gismu.txt .
I think part of the reason I stick with Excel is that my eyesight isn't that good and I need the colors and zoomable interface to make sure I'm reading the words right. A single mistake like misreading a schwa as an /a/ would destroy any words that depend on that morpheme since that kind of mistake would never appear in nature. But another reason is that I need Excel's sort function ... if you use a text file, how are you ever going to be able to alphabetize it? The part you have right now looks alphabetized, .... do you do that by hand?
That said, Excel or some other program could easily import that text file, and resort it in the event you want a reverse lookup or to sort the list irrespective of the headwords. Ive had to sort my dictionary by something other than the headword several times so far. But your setup looks like it could be converted to other formats more easily than something like Excel.
I think part of the reason I stick with Excel is that my eyesight isn't that good and I need the colors and zoomable interface to make sure I'm reading the words right. A single mistake like misreading a schwa as an /a/ would destroy any words that depend on that morpheme since that kind of mistake would never appear in nature. But another reason is that I need Excel's sort function ... if you use a text file, how are you ever going to be able to alphabetize it? The part you have right now looks alphabetized, .... do you do that by hand?
That said, Excel or some other program could easily import that text file, and resort it in the event you want a reverse lookup or to sort the list irrespective of the headwords. Ive had to sort my dictionary by something other than the headword several times so far. But your setup looks like it could be converted to other formats more easily than something like Excel.
Re: Lexicon organisation
Yeah, my verbals work more or less like brivla in Lojban except that, for the place structures, I don't just use numbering or order but cases because it's hard to remember the argument structure of each brivla in Lojban. Like, from what I remember, the word klama is something like "go/come". The first place x1 is the "goer", x2 is I think ... the destination, x3 ... the surface upon which x1 moves and x4 is the manner, maybe? Or is it the source of the movement? If you forget, you end up saying something completely different from what you intended.Pabappa wrote: ↑Wed Dec 26, 2018 10:01 am Your list reminds me a bit of http://www.lojban.org/publications/wordlists/gismu.txt .
Using actual cases makes that unlikely. It also makes it slightly more natlangy, and frees up the word order. (I know you can use reordering particles in Lojban, but, bah, hard to learn!). I use the dative case for recipients and destinations (as well as experiencers of sensory verbs), the ablative is obviously going to be the source of the movement, the manner can be expressed with an instrumental argument or with an adverbial clause introduced by the particle lo (which, in reality is only coincidentally similar to lejo, the comitative case of the complementiser, but it's used fairly similarly and can plausibly be explained as a shortened form of it). Like, sometimes I forget whether a verbal follows the typical experiential pattern, such as
- xeva :: (v) is <visible> to |D|; |D| <sees> |N|
- mahu :: (v) is <known> to/by |D|; is <knowledge> held by |D|; |D| <knows> |N|
- lai :: (v) is <loved> by |D|; is <dear> to |D|; |D| <loves> |N|
- zau :: (v) <doesn't know> |T|; is <ignorant> <unaware> <unknowing> of |T|
T = topical case, i.e. "about"
I mostly view the text file in Wordpad rather than Notepad. I got into the habit years ago because Wordpad would load big files quicker than notepad, but now I don't notice much of a difference except that searching is easier in Wordpad (it's precise in Notepad, either forwards or backwards, but to search the whole thing requires more mouse clicks than in Wordpad), and also, you can zoom easily, change the display font easily etc (although of course not save font changes into the txt file). What do you use colours for? Do you see parts of speech quickly and things like that?I think part of the reason I stick with Excel is that my eyesight isn't that good and I need the colors and zoomable interface to make sure I'm reading the words right. A single mistake like misreading a schwa as an /a/ would destroy any words that depend on that morpheme since that kind of mistake would never appear in nature.
Yeah, as I come up with new words, I put them in the right place. Occasionally I find words that are out of place, but I know the alphabet pretty well, so it's not too much of an issue. I've never needed to sort by English translation either ... I can just search with "<" to find the word or beginning of a word I need.But another reason is that I need Excel's sort function ... if you use a text file, how are you ever going to be able to alphabetize it? The part you have right now looks alphabetized, .... do you do that by hand?
Yeah, getting something to parse it and put everything into the right columns or whatever is way beyond me, but I know it is possible, at least in theory. I got the idea from dict.cc, where you can download whole dictionary databases as text files and they use the double colons between the headword and the entry ... but they also have multiple copies of the headword for each translation, and I prefer to just use angle brackets and semicolons to figure out where the translations start and end and which bits can be swapped out. Being able to search easily makes very little a problem so far.That said, Excel or some other program could easily import that text file, and resort it in the event you want a reverse lookup or to sort the list irrespective of the headwords. Ive had to sort my dictionary by something other than the headword several times so far. But your setup looks like it could be converted to other formats more easily than something like Excel.
Glossing Abbreviations: COMP = comparative, C = complementiser, ACS / ICS = accessible / inaccessible, GDV = gerundive, SPEC / NSPC = (non-)specific, A/ₐ = agent, E/ₑ = entity (person or thing)
________
MY MUSIC | MY PLANTS | ILIAQU
________
MY MUSIC | MY PLANTS | ILIAQU
-
Kuchigakatai
- Posts: 1307
- Joined: Mon Jul 09, 2018 4:19 pm
Re: Lexicon organisation
You've got a mistake in the entry "zaliu". You have numbers there instead of word classes.
I really like it. Lately I've been making a lot of small conlangs, so I've been doing something very similar to that, instead of writing software to manage a proper database.
Code: Select all
{ha} <su> <ese> <esa> <eso>
$cpr su (posesor de tercera persona singular inanimada)
$cpr ese, esa, eso (sujeto átono o régimen átono de tercera persona singular inanimada)
{haido} <párrafo> @lenguaje
$sc párrafo
{hanko} <yerno> <nuera> @familia
$sc yerno, nuera
{hano} <ese> <esa> <eso>
$pron ese, esa, eso (sujeto tónico o régimen tónico de tercera persona singular inanimada)
{harco} <quijada> @cuerpo
$sc quijada
{harmen} <dormir> @fisiología
$vi duerme
{haske} <hoja> <verde> @botánica @color
$sc hoja
$adj verde
{haspro} <cráter>
$sc cráter
{hatti} <ropa> <prenda> @ropa
$sc prenda de vestir
#vadda hatter &se pone la ropa
#lupa hatter &se quita la ropa
{hauke} <comer> @fisiología
$vt come [A:algo]
$vt ((coloc.)) estudia [A:algo]
$vt ((coloc.)) acaba [A:con algn] [ta N:en una discusión]
$vm ((coloc.)) se contradice
$vm ((coloc.)) se acaban [ta N:en una discusión]
{heiti} <ayer> @tiempo
$su el día de ayer
$adv ayer
{heko} <tres> @matemática
$adj tres
{heo} <tiempo> @tiempo
$sc período de tiempo [la C:de hacer]
#heo daita ya hino &tiene tiempo
{herci} <delta> @geografía
$sc delta (de un río)
{hi} <su> <él> <ella>
$cpr su (posesor de tercera persona singular animada)
$cpr él, ella (sujeto átono o régimen átono de tercera persona singular animada)
{hino} <él> <ella>
$pron él, ella (sujeto tónico o régimen tónico de tercera persona singular animada)
{hintro} <aire>
$sm aire
{hise} <decir> <hablar> <pronunciar> @lenguaje
$vt dice [A:algo]
$vt dice [je C:que]
$vt pronuncia [A:una palabra] [vin N:de una manera]
$vt dice [A:algo] [ta N:en un idioma]; habla [ta N:un idioma]
$vt habla [mi N:con algn]
$vt le habla [mi A:a alguien (sin dejarlo,a hablar)]
$vm habla solo,a
{hono} <universo> <mundo>
$su el universo, el mundo
{huki} <hielo> @agua
$sm hielo
{huro} <pez> <pescado> @zoología
$sc pez
$sc pescado
As you can probably tell, the main difference is that I don't mark the reverse lookups in the translation equivalents (as you do with your angle brackets <...>), partly because verbal translation equivalents may have a different stem (dormir ~ duerme, decir ~ dice) so I list reverse lookups in Spanish citation forms elsewhere in the entry (after the headword), partly because any attestation of a reverse lookup would generally be fine, partly because some reverse lookups would be too redundant (as it would be seen in the entry {hise} if I marked every dice and habla as <dice> and <habla>).
-
Ryan of Tinellb
- Posts: 70
- Joined: Mon Jul 09, 2018 6:01 am
Re: Lexicon organisation
An entry from my dictionary. I've been mucking with the search function over the last few days, which is why the 404 page doesn't look the same as ordinary search. Other than that, it works well enough for me.
High Lulani and its descendants at Tinellb.com.
Re: Lexicon organisation
Ooh, good catch. Thanks! I just forgot the word classes. The numbers were on purpose. Now it's:
Code: Select all
• zaitia :: (v) is <guts> <entrails> <intestines> <internal organs> of |G| {bod}
• zaliu :: 1. (v) is a <slug> <land slug> [shell-less land-living gastropod] {fau}
2. (v) is <grease> <axle grease> [lubricant used to grease the axles of an 'ozuuo'] {Qu}
• zamita :: (v) is <Saturday> {loan} {DE} {Earth}I really like your formatting! I mean, I find the angle brackets ugly on your headwords, but it's all very logically laid out and would be easy for a computer program to read as a database, I'm sure. I like the separate lines. I didn't think of that, except for sub-entries and examples.I really like it. Lately I've been making a lot of small conlangs, so I've been doing something very similar to that, instead of writing software to manage a proper database.
Wow, that looks like a lot of work! Nicely presented!! Did you use Lexique to help you make it or are you one of those smart people that can just do stuff like this?Ryan of Tinellb wrote: ↑Thu Dec 27, 2018 3:06 am An entry from my dictionary. I've been mucking with the search function over the last few days, which is why the 404 page doesn't look the same as ordinary search. Other than that, it works well enough for me.
Glossing Abbreviations: COMP = comparative, C = complementiser, ACS / ICS = accessible / inaccessible, GDV = gerundive, SPEC / NSPC = (non-)specific, A/ₐ = agent, E/ₑ = entity (person or thing)
________
MY MUSIC | MY PLANTS | ILIAQU
________
MY MUSIC | MY PLANTS | ILIAQU
-
Ryan of Tinellb
- Posts: 70
- Joined: Mon Jul 09, 2018 6:01 am
Re: Lexicon organisation
No, there's no fancy linguistics-specific stuff here; it's just html. I use my own version of an html editor, which I've been working on for a couple of years now.
High Lulani and its descendants at Tinellb.com.
Re: Lexicon organisation
OK, so you're one of those smart people who can just do stuff like this. You're allowed to call yourself smart!Ryan of Tinellb wrote: ↑Fri Dec 28, 2018 4:54 amNo, there's no fancy linguistics-specific stuff here; it's just html. I use my own version of an html editor, which I've been working on for a couple of years now.
Nice work anyway!
Glossing Abbreviations: COMP = comparative, C = complementiser, ACS / ICS = accessible / inaccessible, GDV = gerundive, SPEC / NSPC = (non-)specific, A/ₐ = agent, E/ₑ = entity (person or thing)
________
MY MUSIC | MY PLANTS | ILIAQU
________
MY MUSIC | MY PLANTS | ILIAQU
Re: Lexicon organisation
I'd be very interested to see this. Is it available anywhere so I can have a look?Ryan of Tinellb wrote: ↑Fri Dec 28, 2018 4:54 amNo, there's no fancy linguistics-specific stuff here; it's just html. I use my own version of an html editor, which I've been working on for a couple of years now.
Personally, I haven't gotten to the stage yet in any of my conlangs where I've even needed to organise my lexicon. I imagine that if I did need some organisational tool at some point, I'd use one of SIL's tools, or Excel, or possibly my own tool (like Ryan of Tinellb has done above). Actually, for me, the biggest problem is keeping my lexicon in sync with example sentences. I tend to use lots of example sentences in my grammars, but I also tend to change words and affixes a lot, and so if I decide to change a word or affix I need to go back and look through all my example sentences to change all its occurrences, and then I need to go back again and check I haven't missed anything... which I usually do. And I can't use find-and-replace, because that matches all the occurrences in English words as well. I'd be really interested to know how everyone else solves this (or if they even have the same problem at all).
Conlangs: Scratchpad | Texts | antilanguage
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
-
chris_notts
- Posts: 682
- Joined: Tue Oct 09, 2018 5:35 pm
Re: Lexicon organisation
Yes, definitely yes. It is a problem - I usually do a first pass searching for e.g. MORPHEME1- or -MORPHEME1 since I always have interlinear glosses in my examples, so if I know the reference shape of the morpheme I can hopefully find it. This also helps if the morpheme is also common in the English text, since the dash (-) weeds out English words containing the same sequence of letters.bradrn wrote: ↑Fri Dec 28, 2018 4:49 pm Personally, I haven't gotten to the stage yet in any of my conlangs where I've even needed to organise my lexicon. I imagine that if I did need some organisational tool at some point, I'd use one of SIL's tools, or Excel, or possibly my own tool (like Ryan of Tinellb has done above). Actually, for me, the biggest problem is keeping my lexicon in sync with example sentences. I tend to use lots of example sentences in my grammars, but I also tend to change words and affixes a lot, and so if I decide to change a word or affix I need to go back and look through all my example sentences to change all its occurrences, and then I need to go back again and check I haven't missed anything... which I usually do. And I can't use find-and-replace, because that matches all the occurrences in English words as well. I'd be really interested to know how everyone else solves this (or if they even have the same problem at all).
Unfortunately that doesn't always catch everything, so occasionally I have to go through, check, and try to spot the errors based on what I know I've changed recently.
Re: Lexicon organisation
Good idea! I never even thought about using glosses - mostly because the conlang I'm working on now hasn't been developed enough for me to put glosses in.chris_notts wrote: ↑Fri Dec 28, 2018 5:50 pmYes, definitely yes. It is a problem - I usually do a first pass searching for e.g. MORPHEME1- or -MORPHEME1 since I always have interlinear glosses in my examples, so if I know the reference shape of the morpheme I can hopefully find it. This also helps if the morpheme is also common in the English text, since the dash (-) weeds out English words containing the same sequence of letters.bradrn wrote: ↑Fri Dec 28, 2018 4:49 pm Personally, I haven't gotten to the stage yet in any of my conlangs where I've even needed to organise my lexicon. I imagine that if I did need some organisational tool at some point, I'd use one of SIL's tools, or Excel, or possibly my own tool (like Ryan of Tinellb has done above). Actually, for me, the biggest problem is keeping my lexicon in sync with example sentences. I tend to use lots of example sentences in my grammars, but I also tend to change words and affixes a lot, and so if I decide to change a word or affix I need to go back and look through all my example sentences to change all its occurrences, and then I need to go back again and check I haven't missed anything... which I usually do. And I can't use find-and-replace, because that matches all the occurrences in English words as well. I'd be really interested to know how everyone else solves this (or if they even have the same problem at all).
Unfortunately that doesn't always catch everything, so occasionally I have to go through, check, and try to spot the errors based on what I know I've changed recently.
(Another idea, building on yours - why not try to 'set off' glosses from the rest of the text by putting a symbol around each morpheme, so something like {word1}-{ACC} {word2}-{1s}>{2p}? I might actually try that - it looks like it could work. On the other hand, it makes the glosses a bit harder to read, so there's always that tradeoff...)
Conlangs: Scratchpad | Texts | antilanguage
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
-
Ryan of Tinellb
- Posts: 70
- Joined: Mon Jul 09, 2018 6:01 am
Re: Lexicon organisation
It's on GitHub at https://github.com/RyanofTinellb/ConlangWebsiteCreation.bradrn wrote: ↑Fri Dec 28, 2018 4:49 pmI'd be very interested to see this. Is it available anywhere so I can have a look?Ryan of Tinellb wrote: ↑Fri Dec 28, 2018 4:54 amNo, there's no fancy linguistics-specific stuff here; it's just html. I use my own version of an html editor, which I've been working on for a couple of years now.
It's nowhere near ready for public use yet, but feel free to clone or download. It's written in Python 2.7, and works well enough for me under Windows 10. Once I feel confident that it's at least somewhat ready, I'll make a proper announcement.
High Lulani and its descendants at Tinellb.com.