
| lexical set | F1 | F2 |
| BATH-PALM-START | 833.87 | 1268.12 |
| CURE | 503.06 | 864.41 |
| DRESS | 596.14 | 1883.57 |
| FLEECE | 409.59 | 2529.61 |
| FOOT | 407.50 | 1300.73 |
| GOOSE | 292.98 | 1704.35 |
| KIT | 462.30 | 2115.76 |
| LOT-CLOTH | 637.74 | 1111.52 |
| NEAR | 479.06 | 2091.70 |
| NURSE | 602.30 | 1548.64 |
| SQUARE | 701.30 | 1904.80 |
| STRUT | 646.86 | 1358.66 |
| THOUGHT-NORTH-FORCE | 509.62 | 904.21 |
| TRAP | 878.16 | 1581.52 |
| commA-lettER | 697.57 | 1336.06 |
| happY | 344.20 | 2328.34 |
English vowel systems and lexical sets
Re: English vowel systems and lexical sets
Given my relative lack of skill in the art of praatcraft I don't want to do a whole bunch of labour that turns out to be flawed. Instead, I got one set of formant frequencies for each monophthong (based on the example words for English lexical sets on Wikipedia) and am sharing the recordings I used for others to make better or more detailed deductions.
Re: English vowel systems and lexical sets
Here's Ketsuban's vowels fairly roughly charted:

It looks like you've got a NORTH/THOUGHT/FORCE/CURE merger (at least in most words) and a STRUT/schwa merger.
I'd say you've got:
KIT /e/
FOOT /ɵ/
DRESS /ɛ/
STRUT~schwa /ɜ/
LOT~CLOTH /ɒ̈/
TRAP /a̟/
happY /ɪ̟/
FLEECE /ɪ̟ː/
GOOSE /ʏː/
NEAR /eː/
N/T/F/C /ɔ̟ː/
SQUARE /ɛ̞ː/
NURSE /ɜː/
B/P/S /äː/
I'm mostly surprised by how low your high front vowels are. Your "fleece" would fall within the range of my "square", and your "kit" (460/2115) is almost identical to my "dress" (461/2139). And there are people in New Zealand with much higher dresses than mine (not in the sense that they are wearing very revealing garments, but in the sense that their dialect has undergone a chain shift by which the DRESS vowel is raised into high front position).
It looks like you've got a NORTH/THOUGHT/FORCE/CURE merger (at least in most words) and a STRUT/schwa merger.
I'd say you've got:
KIT /e/
FOOT /ɵ/
DRESS /ɛ/
STRUT~schwa /ɜ/
LOT~CLOTH /ɒ̈/
TRAP /a̟/
happY /ɪ̟/
FLEECE /ɪ̟ː/
GOOSE /ʏː/
NEAR /eː/
N/T/F/C /ɔ̟ː/
SQUARE /ɛ̞ː/
NURSE /ɜː/
B/P/S /äː/
I'm mostly surprised by how low your high front vowels are. Your "fleece" would fall within the range of my "square", and your "kit" (460/2115) is almost identical to my "dress" (461/2139). And there are people in New Zealand with much higher dresses than mine (not in the sense that they are wearing very revealing garments, but in the sense that their dialect has undergone a chain shift by which the DRESS vowel is raised into high front position).
Re: English vowel systems and lexical sets
I was able to record my own (monophthongal) vowels today:
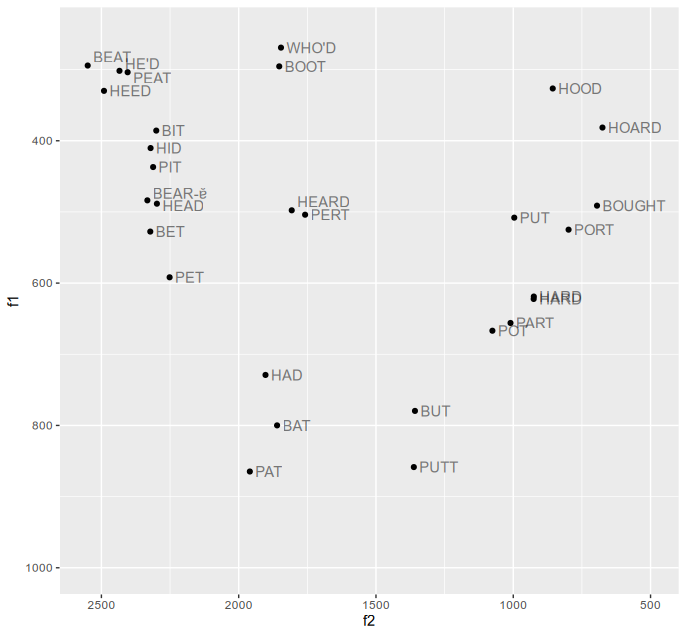
In IPA I’d write these as:
KIT [ɪ]
FOOT [ʊ~o̟]
DRESS [e~e̞]
STRUT [ɐ]
LOT/CLOTH [ɔ]
TRAP [æ~ɛ̞]
FLEECE [iː]
GOOSE [ʉ̟ː]
NORTH/FORCE/THOUGHT [oː~o̞ː]
SQUARE [eː]
NURSE [ɘ̟ː]
BATH/PALM/START [ʌː]
Some thoughts on this:
In IPA I’d write these as:
KIT [ɪ]
FOOT [ʊ~o̟]
DRESS [e~e̞]
STRUT [ɐ]
LOT/CLOTH [ɔ]
TRAP [æ~ɛ̞]
FLEECE [iː]
GOOSE [ʉ̟ː]
NORTH/FORCE/THOUGHT [oː~o̞ː]
SQUARE [eː]
NURSE [ɘ̟ː]
BATH/PALM/START [ʌː]
Some thoughts on this:
- I think I hyperarticulated a bit in some cases: for instance, many voiced stops ended up with negative VOT. The worst-affected was ‘bear’, which I somehow said as [beː.ɐ̆]. But all the vowels sounded representative of my usual speech (even in ‘bear’ it didn’t affect the main vowel).
- SQUARE and LOT/CLOTH had only one representative each. I didn’t record the short vowels COMMA/LETTER and HAPPY, though I’d say they’re the same quality as STRUT and FLEECE respectively.
- On the other hand, I accidentally recorded the word ‘hard’ twice. It comes up in almost precisely the same place, which is a good sanity check. ‘Heed’ and ‘he’d’ should be homophones too, but they come out slightly differently.
- I’ve recorded but not plotted the diphthongs. I could plot them as arrows like Darren did, but it would be nice to see if I can plot the actual contours on the vowel chart.
- BATH/PALM/START was a real surprise here — I had no idea they were so high. I think this is the one vowel which makes my speech so ‘South African’-sounding. (But whenever I spend some time talking to real South Africans, I’m pretty sure it drops down to [ɑː].) I also didn’t realise that my FOOT could be as low as NORTH/FORCE/THOUGHT, but it makes sense since I remember hearing Parisian French [o] and [õ] as /ʊ/ sometimes.
Conlangs: Scratchpad | Texts | antilanguage
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Re: English vowel systems and lexical sets
One thing I find interesting is that I don't hear my own rounded front vowels, especially mid ones, like I do, say, German ones. I perceive my own as essentially transparent allophones of my rounded back vowels to the point that I didn't realize they were so far front until I recorded them with Praat (except for toot, but I would transcribe that as [tsʲʰʉʔ] because of the influence of the glottal stop). Conversely, I perceive German rounded mid front vowels as having a 'rhotic' quality that mine native ones don't have. This might be due to endolabialness versus exolabialness; my own rounded front vowels are very endolabial, whereas when I try to emulate another language, such as German's, rounded front vowels I pronounce them much more exolabially.
Yaaludinuya siima d'at yiseka wohadetafa gaare.
Ennadinut'a gaare d'ate eetatadi siiman.
T'awraa t'awraa t'awraa t'awraa t'awraa t'awraa t'awraa.
Ennadinut'a gaare d'ate eetatadi siiman.
T'awraa t'awraa t'awraa t'awraa t'awraa t'awraa t'awraa.
-
anteallach
- Posts: 402
- Joined: Sun Aug 12, 2018 3:11 pm
- Location: Yorkshire
Re: English vowel systems and lexical sets
| Lexical set(s) | Word used | Average F1 | Average F2 |
| FLEECE | beet | 314 | 2,341 |
| GOOSE | boot | 357 | 1,608 |
| THOUGHT | bought | 457 | 845 |
| KIT | pit | 472 | 2,023 |
| FOOT | put | 476 | 1,085 |
| GOAT | boat | 504 | 1,194 |
| NURSE | Bert | 517 | 1,443 |
| LOT/CLOTH | pot | 617 | 849 |
| STRUT | putt | 631 | 1,046 |
| START | Bart | 716 | 1,067 |
| SQUARE | pair | 773 | 1,776 |
| DRESS | pet | 781 | 1,861 |
| MOUTH | bout | 843 | 1,637 |
| TRAP/BATH | pat | 858 | 1,319 |
I also recorded bait but it was clearly diphthongal. It is a little surprising that my FACE seems to be much more likely to be a diphthong than my GOAT, but I was already aware of that tendency. And if you're wondering whether people ever have any difficulty understanding my MOUTH vowel, the answer is "yes"!
The biggest surprise for me is how high my THOUGHT seems to be.
-
anteallach
- Posts: 402
- Joined: Sun Aug 12, 2018 3:11 pm
- Location: Yorkshire
Re: English vowel systems and lexical sets
The roundedness also doesn't seem to be affecting the formants much. Normally roundedness reduces F2 a bit, but in your plots those vowels' F2s are pretty much the same as those of the unrounded front vowels at the same heights.Travis B. wrote: ↑Sat Dec 28, 2024 10:32 pm One thing I find interesting is that I don't hear my own rounded front vowels, especially mid ones, like I do, say, German ones. I perceive my own as essentially transparent allophones of my rounded back vowels to the point that I didn't realize they were so far front until I recorded them with Praat (except for toot, but I would transcribe that as [tsʲʰʉʔ] because of the influence of the glottal stop). Conversely, I perceive German rounded mid front vowels as having a 'rhotic' quality that mine native ones don't have. This might be due to endolabialness versus exolabialness; my own rounded front vowels are very endolabial, whereas when I try to emulate another language, such as German's, rounded front vowels I pronounce them much more exolabially.
Re: English vowel systems and lexical sets
I'm so confident I merge THOUGHT-NORTH-FORCE that I didn't even bother recording the wordlists for NORTH or FORCE; I know full well that I'm nonrhotic, they don't sound any different when I say them, and they all rhyme. I agree with Travis that CURE seems dubious as a lexical set—"pure" (586.92, 1211.53) and "poor" (495.54, 862.74) are audibly different in the recording.
Should try again with the H_D, B_T, P_T template method?
Re: English vowel systems and lexical sets
I plotted anteallach’s vowels:
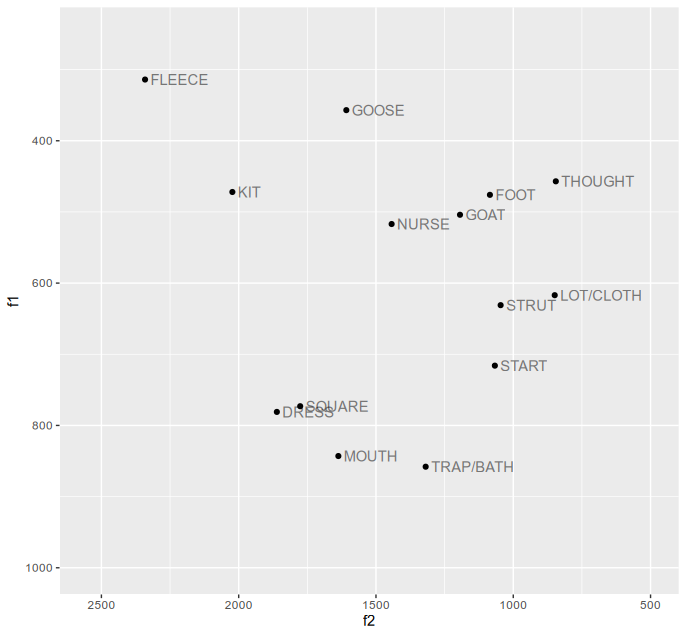
I note with interest that DRESS and MOUTH are hovering around [æ]. This is something I noticed recently in another speaker from London (which IIRC is where anteallach is from too, correct?).
I note with interest that DRESS and MOUTH are hovering around [æ]. This is something I noticed recently in another speaker from London (which IIRC is where anteallach is from too, correct?).
Conlangs: Scratchpad | Texts | antilanguage
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Re: English vowel systems and lexical sets
This may be a stupid question, but what program/app/website are people (bradrn, Darren, Travis) using to create their chart? I'm using Libre Office Calc, and it seems unable to create an XY scatter chart with a label on each point. (I assume that Excel is similarly unable to do this.)
Re: English vowel systems and lexical sets
I was using gnuplot.jcb wrote: ↑Sun Dec 29, 2024 7:47 pm This may be a stupid question, but what program/app/website are people (bradrn, Darren, Travis) using to create their chart? I'm using Libre Office Calc, and it seems unable to create an XY scatter chart with a label on each point. (I assume that Excel is similarly unable to do this.)
Yaaludinuya siima d'at yiseka wohadetafa gaare.
Ennadinut'a gaare d'ate eetatadi siiman.
T'awraa t'awraa t'awraa t'awraa t'awraa t'awraa t'awraa.
Ennadinut'a gaare d'ate eetatadi siiman.
T'awraa t'awraa t'awraa t'awraa t'awraa t'awraa t'awraa.
Re: English vowel systems and lexical sets
I used R, plotting with ggplot2. (Partly following the tutorial I linked previously, but mostly using the little knowledge of R that I already have.)jcb wrote: ↑Sun Dec 29, 2024 7:47 pm This may be a stupid question, but what program/app/website are people (bradrn, Darren, Travis) using to create their chart? I'm using Libre Office Calc, and it seems unable to create an XY scatter chart with a label on each point. (I assume that Excel is similarly unable to do this.)
Conlangs: Scratchpad | Texts | antilanguage
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Re: English vowel systems and lexical sets
Well, I already did it by just plotting the points by hand with mspaint, so I'm not going to bother writing gnuplot or R code. It's imprecise, but oh well.
So, here's mine:

Note: Y Axis = F1, X Axis = F2
I've never actually measured the formants of my vowels before, so seeing this is very interesting! Thoughts and notes:
(1) I knew that my /u/ was unrounded, but I didn't know it was so middle and low!
(2) I didn't think that my /I/ and /e/, and /U/ and /o/ were so close together.
(3) I didn't know that my /@/ (in BUT) (or perhaps I should call it /V/ now) was as far back as my /A/.
(4) None of my vowels go lower than 750, but other people's in this thread peak around 900.
(5) My accent is rhotic, so BERT has a syllabic /r/.
(6) Besides the /u/, it's pretty symmetric.
(7) I've never measured my formants or used Praat before, so I probably didn't do it 100% correctly.
Thanks for posting the link to the tutorial, bradrn!
So, here's mine:
Note: Y Axis = F1, X Axis = F2
I've never actually measured the formants of my vowels before, so seeing this is very interesting! Thoughts and notes:
(1) I knew that my /u/ was unrounded, but I didn't know it was so middle and low!
(2) I didn't think that my /I/ and /e/, and /U/ and /o/ were so close together.
(3) I didn't know that my /@/ (in BUT) (or perhaps I should call it /V/ now) was as far back as my /A/.
(4) None of my vowels go lower than 750, but other people's in this thread peak around 900.
(5) My accent is rhotic, so BERT has a syllabic /r/.
(6) Besides the /u/, it's pretty symmetric.
(7) I've never measured my formants or used Praat before, so I probably didn't do it 100% correctly.
Thanks for posting the link to the tutorial, bradrn!
Re: English vowel systems and lexical sets
Wait, it’s unrounded? I haven’t heard of that before…
Meanwhile, I had a go at plotting my diphthongs (based on https://joeystanley.com/blog/geomtextpath/):
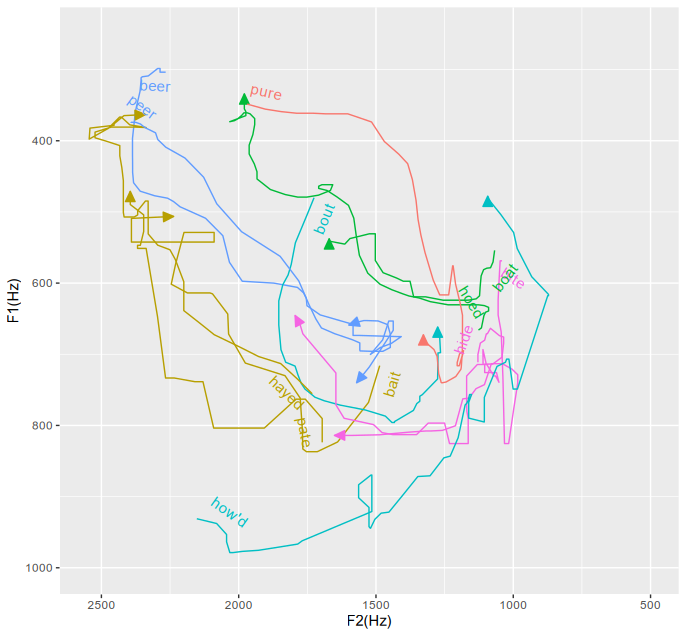
Here each line shows the (smoothed) contour of the diphthong in each word, coloured by lexical sets. I tried my best, but the plot is rather confusing! So I’ll describe each vowel in turn:
NEAR (‘beer’, ‘peer’) is reasonably simply [i.ɜ]. It’s not obvious from the plot, but this isn’t actually a true diphthong — the spectogram clearly shows two vowels with a short transition between them.
FACE (‘hayed’, ‘bait’, ‘pate’) looks like [æ͡i]. Comparing to my last plot, the ending point looks closer to [i] than to [ɪ], though I suppose you could hyper-narrowly transcribe it [æ͡ɪ̝].
GOAT (‘hoed’, ‘boat’) is something like [ɔ̟͡ʉ̟ ~ ɔ̟͡ɜ]. The ending point varies quite a bit between the two words here — as if ‘boat’ only has the first half of the diphthong. Previously I’ve transcribed the starting point of this diphthong as [ɞ], but it looks slightly more back than that, closer to [ɔ] (which is my LOT/CLOTH).
CURE (‘pure’) is nearly the reverse of GOAT, being [(j)ʉ̟͡ʌ̟]. Previously I’ve transcribed the ending as [ɐ] or [ɜ], but as with GOAT it seems to be further back. The contour here seems to cut off the initial glide [j], but in the spectrogram it’s definitely present.
[EDIT: on reflection, perhaps I should rather transcribe this [(j)ɵ͡ʌ̟]. I think this more accurately reflects the pathway shown on the plot.]
I didn’t record any words in POOR, but it’s definitely different from CURE — I’d guess it’s something like [ʊ͡ʌ].
PRICE (‘bite’, ‘hide’) was the biggest surprise. From the curves here it seems to be something like [ʌ͡æ ~ ʌ͡ɛ], with a low ending point. In retrospect this shouldn’t have been so surprising, since I know that in South African English it has a tendency to monophthongise to something like [ɑː]. But I’m pretty sure there’s other situations in which I say it as something more like [ʌ͡e], even if it never goes as high as [ɪ] or [i].
MOUTH (‘how’d’, ‘bout’) is very, very confusing. I think what’s happening here is that in ‘bout’ it’s heavily influenced by the preceding /b/, and I didn’t cut that portion out of the contour well enough. On the other hand, ‘how’d’ has an almost unbelievably fronted beginning point. There was also a third word ‘pout’ where the data made no sense at all (it seems inconsistent with the spectrogram). I think I’m going to transcribe this one [æ͡o], but with a lot of uncertainty.
Conlangs: Scratchpad | Texts | antilanguage
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
-
anteallach
- Posts: 402
- Joined: Sun Aug 12, 2018 3:11 pm
- Location: Yorkshire
Re: English vowel systems and lexical sets
Not London, no: my accent is a weird hybrid but the base is probably best described as "middle class Northern". Monophthongal MOUTH crops up in a few places in the UK (and also Pittsburgh in the US).
The plot does suggest that my accent is curiously lacking in mid front vowels. A monophthongal FACE (which I'm sure I do sometimes produce, just not in bait) would partly fill that gap, but the short vowels are still strangely distributed.
Re: English vowel systems and lexical sets
I was using Libre Office Calc myself, but then labelling the points manually in Preview.jcb wrote: ↑Sun Dec 29, 2024 7:47 pm This may be a stupid question, but what program/app/website are people (bradrn, Darren, Travis) using to create their chart? I'm using Libre Office Calc, and it seems unable to create an XY scatter chart with a label on each point. (I assume that Excel is similarly unable to do this.)

Re: English vowel systems and lexical sets
Admit it, you really did that by drawing with a mouse, didn't you?bradrn wrote: ↑Sun Dec 29, 2024 11:00 pm Meanwhile, I had a go at plotting my diphthongs (based on https://joeystanley.com/blog/geomtextpath/):
(that funny picture)
"But he had reckoned without my narrative powers! With one bound I narrated myself up the wall and into the bathroom, where I transformed him into a freestanding sink unit.
We washed our hands of him, and lived happily ever after."
We washed our hands of him, and lived happily ever after."
Re: English vowel systems and lexical sets
No, this really and truly is a trace of my diphthongs as extracted from Praat. In fact the real data was even more wobbly than that: I had to smooth it a bit to get something useful.alice wrote: ↑Mon Dec 30, 2024 2:42 pmAdmit it, you really did that by drawing with a mouse, didn't you?bradrn wrote: ↑Sun Dec 29, 2024 11:00 pm Meanwhile, I had a go at plotting my diphthongs (based on https://joeystanley.com/blog/geomtextpath/):
(that funny picture)
(That linked article shows that you can fit a GAM to get something more sensible, but I don’t actually know what a GAM is or how to use one, and messing around in R without fully understanding what you’re doing is a surefire path to the R Inferno…)
Conlangs: Scratchpad | Texts | antilanguage
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)
Software: See http://bradrn.com/projects.html
Other: Ergativity for Novices
(Why does phpBB not let me add >5 links here?)

Re: English vowel systems and lexical sets
OK, here's my data. Hopefully I did it right.
| Lexical set(s) | Word used | Average F1 | Average F2 |
| FLEECE | beet | 268 | 2281 |
| GOOSE | boot | 309 | 1473 |
| THOUGHT/CLOTH | bought | 557 | 587 |
| KIT | pit | 380 | 2337 |
| FOOT | put | 415 | 734 |
| GOAT | boat | 454 | 1310 |
| NURSE | Bert | 490 | 1271 |
| LOT | pot | 669 | 995 |
| STRUT | putt | 600 | 1081 |
| START | Bart | 642 | 771 |
| SQUARE | pair | 481 | 1317 |
| CURE | pure | 288 | 1536 |
| NORTH/FORCE | port | 360 | 570 |
| DRESS | pet | 594 | 1970 |
| MOUTH | bout | 647 | 1607 |
| PRICE | pie | 657 | 1058 |
| CHOICE | poi | 371 | 1147 |
| TRAP/BATH | pat | 750 | 1712 |
| PALM | Praat | 666 | 889 |
| FACE | pate | 470 | 2069 |
Re: English vowel systems and lexical sets
I just checked my native [ø̞(ː)] versus my rendering of StG [øː], which I checked for correctness based on comparison with German on YouTube, and then watched myself pronounce each of them in front of a mirror, and the difference (aside from closeness) really seems to be that my native [ø̞(ː)] is endolabial whereas StG [øː] is exolabial, and only the exolabial [øː] has its characteristic 'rhotic' sound.Travis B. wrote: ↑Wed Jan 01, 2025 1:21 pm There is a street in Milwaukee named Teutonia, which in the dialect here is pronounced /taɪˈtoʊnjə/ [tʰăĕ̯ˈtʰø̞̃ːnjə(ː)]* or /təɪˈtoʊnjə/ [tʰə̆ĕ̯ˈtʰø̞̃ːnjə(ː)]* (both pronunciations feel right to me, but I would favor the former if speaking carefully). This is completely non-obvious to non-locals. My guess is the name is influenced by German dialects in which the historical equivalent to StG /ɔʏ/ has merged with the historical equivalent to StG /aɪ/ as an unrounded diphthong. (These sorts of pronounciations can be heard in things ranging from Anh/aɪ/ser-Busch to the name Pr/aɪ/ssler..)
* Yes, I'm sure these have rounded front vowels. However, you might differ if you heard them recorded, as they don't sound much like, say, StG [øː].
Yaaludinuya siima d'at yiseka wohadetafa gaare.
Ennadinut'a gaare d'ate eetatadi siiman.
T'awraa t'awraa t'awraa t'awraa t'awraa t'awraa t'awraa.
Ennadinut'a gaare d'ate eetatadi siiman.
T'awraa t'awraa t'awraa t'awraa t'awraa t'awraa t'awraa.
Re: English vowel systems and lexical sets
If I intentionally round my lips when saying BOOT, I get (roughly) 1000 Hz (F2) * 350 Hz (F1).Wait, it’s unrounded? I haven’t heard of that before…
How are you exporting and then storing the data for each diphthong from Praat to use it in R?Meanwhile, I had a go at plotting my diphthongs (based on https://joeystanley.com/blog/geomtextpath/):
Last edited by jcb on Mon Jan 06, 2025 3:10 am, edited 1 time in total.