Page 13 of 41
Re: Paleo-European languages
Posted: Wed Oct 28, 2020 6:21 pm
by Nortaneous
Computational phylogeny is garbage and can be ignored.
bradrn wrote: ↑Wed Oct 28, 2020 6:23 am
Talskubilos wrote: ↑Wed Oct 28, 2020 4:14 am
The thing is we're dealing with
substrate loanwords, and unfortunately the material is scanty, so quality primes over quantity.
Hmm, I suspect we’re getting to the root of the disagreement here. In this particular case, I don’t agree that quality is better than quantity: as I said, chance resemblances are very common, so having just a few correspondences doesn’t necessarily prove anything — regardless of whether we’re looking at a poorly-attested substrate or not. (And what do you mean by ‘quality’ anyway?)
Chance resemblances are common, but they become more common as more lexical material is added. Three correspondences between two languages with only a few hundred attested words each is 'qualitatively' more than three correspondences between two languages with comprehensive dictionaries.
If you're comparing a language with only a few hundred attested words (would I be correct in assuming the Gaulish corpus is not very large?) to an entire
family whose living members have comprehensive dictionaries, though... I'm not sure how the numbers work out there.
Talskubilos wrote: ↑Wed Oct 28, 2020 6:41 am
Ares Land wrote: ↑Wed Oct 28, 2020 5:01 amYou've stated the existence of those loanwords as established
fact, which is untenable.
Not more "established fact" that the existence of PIE, which is a
theory.
Man, facts aren't even real. Unless you believe in Descartes' a priori proof of the existence of a benevolent god (or something to equivalent effect), you can't totally rule out Cartesian demons - you can assign something probability epsilon, but not zero. (And even if you do believe in that proof, who's to say the Cartesian demons can't mess with your perception of logic?)
That's not to say you can assign numerical probabilities (or even ranges) to historical-linguistic theories, of course. But there's still some vague and qualitative idea of likelihood. The Proto-Indo-European theory "is more likely than" the Proto-Dene-Yeniseian one because there's more shared and seemingly inherited material - not just lexical material, but morphological and syntactic material, and even poetic set phrases preserved in exact cognates in multiple Indo-European languages. And the Proto-Dene-Yeniseian theory is more likely than the Proto-Amerind one for similar reasons. (At the same time, the theory that says that Finnish and Estonian are related is more likely than the Proto-Indo-European theory, for similar reasons - some Finns apparently "learn Estonian" by memorizing rules for mechanical conversion between the two languages. And the Proto-Romance theory is more likely than the Proto-Indo-European theory for trivial statistical reasons.)
The question is about the weight of the evidence, and the process of examining a theory is about refining this vague qualitative likelihood estimate, by adding to (or subtracting from) the weight of the evidence. There are some methodological points here. Some Starostinites complain that, although comparative reconstruction is taken as the standard of proof for cladistic relationship, you have to have some idea of cladistic relationship before you even know what to compare; but this isn't really a point in the Starostinites' favor. You
do have to have some idea of cladistic relationship before you know what to compare - this can be the general impression of similarity (as originally with PIE), comparison of pronouns (as with Wurm's preliminary classificatory work on Papuan), mass lexical comparison, or whatever. But the process of applying the comparative method is about testing and refining the initial hypothesis - comparison of pronouns produces results that are, in some vague but entirely real way,
less likely than demonstration of regular sound correspondences, inheritance of lexical and morphological material, etc.
Re: Paleo-European languages
Posted: Wed Oct 28, 2020 6:37 pm
by Richard W
Ares Land wrote: ↑Wed Oct 28, 2020 10:30 am
Greenberg posited 1 family where Americanists posited 300. Greenberg quipped about traffic controllers on the Bering strait, but I believe we have quite a wrong view of what Beringia was like.
We think of it as a 'land bridge', but it wasn't so much a bridge as a fairly large area of permanent settlement. There's really nothing precluding it being similar to Australia -- 300 languages and 20 families...
Or 300 languages and *one* family according to Robert Mailhammer!
Re: Paleo-European languages
Posted: Wed Oct 28, 2020 8:57 pm
by Nortaneous
Richard W wrote: ↑Wed Oct 28, 2020 6:37 pm
Ares Land wrote: ↑Wed Oct 28, 2020 10:30 am
Greenberg posited 1 family where Americanists posited 300. Greenberg quipped about traffic controllers on the Bering strait, but I believe we have quite a wrong view of what Beringia was like.
We think of it as a 'land bridge', but it wasn't so much a bridge as a fairly large area of permanent settlement. There's really nothing precluding it being similar to Australia -- 300 languages and 20 families...
Or 300 languages and *one* family according to Robert Mailhammer!
I looked up Mailhammer, and one of his
papers has (from Mallory & Adams 2006) two very strange trees of Indo-European.
In the first one, Tocharian is grouped with Greek (held to be more closely related to Greek than Armenian is, even), and "Core Satem" (Balto-Slavic and Indo-Iranian) is held to be a genetic unit - aren't there subtle differences in the application of satemization in BSl. vs. IIr.? (And doublets, like Lithuanian
akmuo "stone" vs.
ašmuo "edge, blade" < *h2eḱ-mo-... in this case, it seems to me that the more specialized meaning of the satem variant suggests that it's the loan and that the centum variant was inherited, but possibly a comprehensive survey of other such doublets and exceptions would suggest otherwise.)
In the second one, Tocharian seems to be grouped with Paleo-Balkan. Very strange!
But these are both better than the ASJP's treatment of the Romance languages, which is complete nonsense:
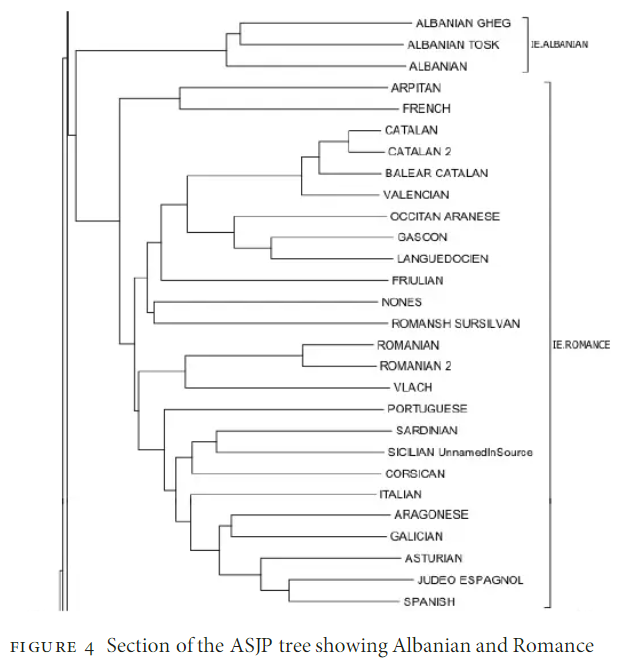
- asjp.png (85.58 KiB) Viewed 7464 times
Not only is Spanish more closely related to Romanian than to French, it's more closely related to both Italian and Sardinian than to Portuguese! And Albanian is a Romance language, but everyone knows
that.
Later on in the paper, we see that Manx is Goidelic, and Saurashtra, in the Gujarati dialect cluster, is Brythonic. OK! And in the ASJP world tree, we discover that Greek is in fact Papuan, and most closely related to Maybrat.
computational_phylogeny.txt
Anyway, given the existence of Meriam Mir, it seems plausible that Papuan languages could've gotten to Australia proper (and been subject to Australian continent-wide sprachbund effects, although fricativelessness isn't terribly rare in Papuan either), which seems like a point against strict monogenesis - there could be either distant relations between Papuan and non-Pama-Nyungan or families that expanded into Australia and then went extinct elsewhere. (Maybe as a side effect of the expansion of Trans-New Guinea or something. Who knows.)
Re: Paleo-European languages
Posted: Wed Oct 28, 2020 9:05 pm
by zyxw59
Dare I ask, what "Romanian 2" and "Catalan 2" are?
Re: Paleo-European languages
Posted: Wed Oct 28, 2020 9:57 pm
by zompist
Nortaneous wrote: ↑Wed Oct 28, 2020 8:57 pm
Not only is Spanish more closely related to Romanian than to French, it's more closely related to both Italian and Sardinian than to Portuguese! And Albanian is a Romance language, but everyone knows
that.
Is my Google fu correct, that ASKP is based on a
40-item basic-vocabulary list? That's, well, awful. Oh wait, it's more scientific because it was done with a computer. The most scientific one they could get from Radio Shack.
I like the way Galician is not only closer to Spanish than to Portuguese, but closer to Italian.
(There's something to be said for Jack Rea's advice on subdividing Romance, which was "don't".)
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 12:25 am
by Nortaneous
zompist wrote: ↑Wed Oct 28, 2020 9:57 pm
Is my Google fu correct, that ASKP is based on a
40-item basic-vocabulary list? That's, well, awful. Oh wait, it's more scientific because it was done with a computer. The most scientific one they could get from Radio Shack.
It's worse: a 40-item basic vocabulary list simplified into highly limited ASCII notation (not even IPA), badly. Take a look at
the English wordlist.
(There's something to be said for Jack Rea's advice on subdividing Romance, which was "don't".)
What about the different developments of the vowels?
(And why does Wikipedia separate Sicilian from Western Romance in its chart? The developments shown are trivially derivable from the Western Romance ones.)
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 4:50 am
by Raphael
zyxw59 wrote: ↑Wed Oct 28, 2020 9:05 pm
Dare I ask, what "Romanian 2" and "Catalan 2" are?
Gritty reboots?
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 5:08 am
by Richard W
Nortaneous wrote: ↑Wed Oct 28, 2020 8:57 pm
I looked up Mailhammer, and one of his
papers has (from Mallory & Adams 2006) two very strange trees of Indo-European.
Mailhammer is reporting on how well or badly ASJP works. He's not endorsing its verdicts. He's explicitly unimpressed by ASJP putting Hindi and Urdu in different branches of Indic. The ASJP uses Levenshtein distances, and there's no attempt to calibrate out sound shifts. (And that's not going to be easy if one uses data sets of size 40.)
Nortaneous wrote: ↑Wed Oct 28, 2020 8:57 pm
In the first one, Tocharian is grouped with Greek (held to be more closely related to Greek than Armenian is, even),...
Levenshtein.
Nortaneous wrote: ↑Wed Oct 28, 2020 8:57 pm
...and "Core Satem" (Balto-Slavic and Indo-Iranian) is held to be a genetic unit - aren't there subtle differences in the application of satemization in BSl. vs. IIr.? (And doublets, like Lithuanian
akmuo "stone" vs.
ašmuo "edge, blade" < *h2eḱ-mo-... in this case, it seems to me that the more specialized meaning of the satem variant suggests that it's the loan and that the centum variant was inherited, but possibly a comprehensive survey of other such doublets and exceptions would suggest otherwise.)
Well, if we accept that a sound change generalises as it spreads, then the historical core of a change should apply. And there are sane believers in "Core Satem".
Nortaneous wrote: ↑Wed Oct 28, 2020 8:57 pm
Later on in the paper, we see that Manx is Goidelic, and Saurashtra, in the Gujarati dialect cluster, is Brythonic. OK! And in the ASJP world tree, we discover that Greek is in fact Papuan, and most closely related to Maybrat.
What is your point? Is it that Mailhammer is too polite about ASJP?
Nortaneous wrote: ↑Wed Oct 28, 2020 8:57 pm
Anyway, given the existence of Meriam Mir, it seems plausible that Papuan languages could've gotten to Australia proper (and been subject to Australian continent-wide sprachbund effects, although fricativelessness isn't terribly rare in Papuan either), which seems like a point against strict monogenesis - there could be either distant relations between Papuan and non-Pama-Nyungan or families that expanded into Australia and then went extinct elsewhere. (Maybe as a side effect of the expansion of Trans-New Guinea or something. Who knows.)
West Torres Straits, the Australian neighbour of Meriam Mir, has actually developed fricatives.
The genetics suggest a rather long separation between Papuans and Australians (37k years). A rather more striking claim is the arrival of people from India 4,000 years ago - obviously looking for fellow retroflex-users?
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 7:11 am
by Richard W
zyxw59 wrote: ↑Wed Oct 28, 2020 9:05 pm
Dare I ask, what "Romanian 2" and "Catalan 2" are?
According to the
ASJP database (start from and use a search button to get the language):
"Catalan" comes from Wiktionary.
"Catalan2" is based on Rodríguez and Martín 2005, Lenguas de la Península Ibérica / Languages of the Iberian Peninsula. Palencia: Ibarantia S. L.
"Romanian" is based on Läƒzäƒrescu and Savin 2004, Universal-Wörterbuch Rumänisch. Berchtesgaden: Langenscheidt.
"Romanian 2" is based on "Schulte 2009" and "Romanian vocabulary. In: Haspelmath, Martin & Tadmor, Uri (eds.), World loanword database. Leipzig: Max Planck Institute for Evolutionary Anthropology, 2270 entries. (Available online at
http://wold.clld.org/vocabulary/8.)"
"Romanian 3" is based on Lange-Kowal 1999, Langenscheidts Universal-Wörterbuch Rumänisch. Berlin und München: Langenscheidt KG. (26th ed.).;
http://northeuralex.org/languages/ron (accessed 2020-01-27).
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 7:22 am
by Richard W
Nortaneous wrote: ↑Thu Oct 29, 2020 12:25 am
's worse: a 40-item basic vocabulary list simplified into highly limited ASCII notation (not even IPA), badly. Take a look at
the English wordlist.
Given that they're using the Levenshtein distance metric, they need something crude. A narrow IPA transcription could even further degrade their performance.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 7:44 am
by WeepingElf
Robert Mailhammer is also a supporter of Theo Vennemann's Pan-Vasconism, which claims that before the spread of IE by Neolithic farmers all of western Europe spoke languages related to Basque.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 8:06 am
by Richard W
(Duplicate post removed)
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 8:32 am
by Richard W
zompist wrote: ↑Wed Oct 28, 2020 9:57 pm
Oh wait, it's more scientific because it was done with a computer. The most scientific one they could get from Radio Shack.
It's more scientific because it is repeatable and there is a precise statement of what they've done. It's intended to remove the subjective element.
The problem lies in acting on identification of the shortcomings of their method. For example, they shortened the list from 100 to 40 because the other 60 were contributing more noise than illumination. Blending in the signal from the other 60 is not easy, especially if the information from the more conservative 40 is being extracted badly.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 9:47 am
by Pabappa

I looked over the graph and think I might have found a few things you all missed ....
From what I can see, Spanish is roughly where it should be, that is, nearer to Portuguese than to Romanian.
This is a chart of vocabulary retention, not of genetic distance, right? That explains the presence of Albanian (it has many Romance loans) and perhaps also explains why French is off by itself (it has many Germanic loans). The fact that the label says "Albanian and Romance" shows that he knows what he's doing.
It would've been nice if they'd used 400 words instead of 40, though. Or maybe even 4000. If theyre using a computer, it shouldnt really matter a whole lot .... computers work pretty fast.
All in all I'd say this chart isn't great, but it's not as terrible as you all are making it out to be, either.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 12:50 pm
by Richard W
Pabappa wrote: ↑Thu Oct 29, 2020 9:47 am
This is a chart of vocabulary retention, not of genetic distance, right? That explains the presence of Albanian (it has many Romance loans) and perhaps also explains why French is off by itself (it has many Germanic loans). The fact that the label says "Albanian and Romance" shows that he knows what he's doing.
It's actually a chart of vocabulary similarity. French's loss of final consonants may have helped isolate it; its possibly unique notation for nasalisation (/*/) and the undefined tilde probably don't help. The paper (Reference 3 in the Wikipedia
ASJP page) on its use to date language splits doesn't inspire confidence - it claims that "weso" and "osso" have a Levenshtein distance of 3 when the answer should be 2 (as they allow replacements with a cost of 1, as confirmed by the upper bound they give for distances).
Pabappa wrote: ↑Thu Oct 29, 2020 9:47 am
It would've been nice if they'd used 400 words instead of 40, though. Or maybe even 4000. If theyre using a computer, it shouldnt really matter a whole lot .... computers work pretty fast.
Unfortunately, their algorithm works better with 40 words than with 100, let alone 400. It is a sad fact that the computational comparative linguistics software around can't handle low grade data. Normally, when one obtains extra samples, the new information is of the same quality as the original data. In comparative linguistics, one starts with the good data, and additional data from a language is frequently of much less worth. The more distantly related the languages, the lower the quality of the extra data.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 3:43 pm
by Talskubilos
WeepingElf wrote: ↑Wed Oct 28, 2020 9:49 amAt least we don't know that it
isn't. What reasons are there to assume that the language(s) of the Clovis people obliterated those of the earlier immigrants completely? Such a scenario may be conceivable (Europe seems to have gone through two waves of language replacement, leaving only few remains of the Neolithic languages - Basque and the three Caucasian families - and probably none of the Paleolithic ones), but so far we AFAIK have no proof.
I disagree. There's some evidence (although not very much) that Basque (and for that matter, also Iberian) could descend from some of the languages spoken by the Steppe People (aka Kurgans). On the other hand, the languages spoken by the Neolithic farmers who colonized the Greece-Balkans area from the Near East would be close relatives of Semitic. I also think a significant proportion of the +2000 reconstructed PIE roots are actually substrate loanwords from the languages spoken by Mesolithic hunter-gatherers.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 5:08 pm
by zompist
Richard W wrote: ↑Thu Oct 29, 2020 8:32 am
zompist wrote: ↑Wed Oct 28, 2020 9:57 pm
Oh wait, it's more scientific because it was done with a computer. The most scientific one they could get from Radio Shack.
It's more scientific because it is repeatable and there is a precise statement of what they've done. It's intended to remove the subjective element.
This is regrettable computolatry. Computers are not free of the "subjective element"; they reproduce the biases of their programmers— and in a more pernicious way because people don't realize that they can be biased.
Every decision made in programming such comparisons is subjective: what data to include and exclude, how the data is represented, how differences are measured, how much those differences are weighted.
And that's before even looking at other aspects of the methodology, such as the bad data that Nortaneous pointed out.
When computers are used to do things humans can't easily do, that's exciting. But to throw out 200 years of human work to replace it with a high-school-level understanding of language change is not "scientific".
As for "repeatable", why do you think historical linguists is not repeatable? Do you think that if linguists started over, they'd randomly group Indic with Chinese or something? There's not many areas of inquiry where so many eyeballs have looked at such a quantity of data.
There are, as these threads have demonstrated, lots of areas of disagreement. Not one of them would be improved by hiding the decisionmaking in a computer program, or pretending that the resulting program is infallible.
The one thing I'll grant you is that the programmers have found a way to automate Joseph Greenberg. They don't seem to have improved on him, however.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 6:08 pm
by Talskubilos
WeepingElf wrote: ↑Fri Oct 23, 2020 2:31 pmI have tried to remember what you claimed I had written it on a FrathWiki page you "couldn't find" because I have "modified the article" since then, but I sincerely
cannot remember to have ever entertained that notion for any language (not even any of my conlangs, BTW). Perhaps
someone else wrote that, but you are just misremembering who had written it? At any rate, I do not entertain the notion
now for
any language. It may have happened
somewhere, but you just can't attribute it to me.
But be it as it may be: Saying that someone said something but "I can't tell you where because he has changed the page since then" is
utterly unacceptable, because that way, you can claim
anything. At least, you misattributed to me something harmless that "just happened" to corroborate your own ideas, but that doesn't really make it better. Also, even if someone once actually said something but
later said that he was wrong and has changed his opinion since then you cannot treat it as if it was his current opinion.
And BTW: What once was written on FrathWiki is not lost, but kept in the history of the relevant page together with information on who wrote it (even histories of deleted pages are still kept on the server), so it would be recoverable.
I've just found your old article:
 http://www.frathwiki.com/index.php?titl ... ldid=70526
Proto-Europic Phonology
http://www.frathwiki.com/index.php?titl ... ldid=70526
Proto-Europic Phonology
The main feature that distinguishes Europic from the other branches of Eurasiatic is its vowel system, which included only three vowels:
*a, *i and
*u, of which
*a was much more frequent than the others. This system is the result of a sound change, the Great Vowel Collapse (GVC), a merger of all Proto-Eurasiatic vowels except
*i and
*u into
*a. Before the GVC, pre-Proto-Europic underwent another change in the vowel system: Resonant-Conditioned Lowering (RCL). Under this rule, high vowels followed by resonants were lowered. The lowered vowels then fell victim to the GVC. This explains the apparent lack of
*CeiR- and
*CeuR- roots in PIE. Also, velar consonants bear traces of the original vowels in that velars next to former front vowels are fronted and velars next to rounded velars are labialized.
As an example of these changes, one might take the PIE root
*kʷel- 'to turn', which appears to have cognates of the shape
*kulV- in Uralic and Altaic languages:
Proto-Eurasiatic
*kulV- >
*kol- (RCL) >
*kʷol- > Proto-Europic
*kʷal- (GVC) > PIE
*kʷel-
This three-vowel system is attested in the Old European hydronymy and can be reconstructed for pre-ablaut Indo-European. In PIE,
*a became
*e/*o/Ø, *i became
*ei/*oi/*i and
*u became
*eu/*ou/*u. In West Europic, the Proto-Europic vowel system was preserved, as evidenced by the Old European river names. It apparently also remained intact in East Europic long enough to influence the Eastern (Indo-Iranian) subbranch of Indo-European in which PIE
*a, *e and
*o all merged into
*a - it appears as if Eastern IE had undergone the GVC twice.
The consonant inventory of Proto-Europic is essentially that of Proto-Indo-European as it is posited by the adherents of the glottalic theory, i.e. the (traditional) PIE voiced stops evolved from glottalized (ejective) stops. Also, in Proto-Europic, palatal consonants as found in other Mitian languages appear to have merged with dental ones. This is accordance with the sound correspondences proposed by Allan R. Bomhard between Proto-Nostratic and Indo-European.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 6:56 pm
by Richard W
Quoting WeepingElf from off-site,
Talskubilos wrote: ↑Thu Oct 29, 2020 6:08 pm
Also, in Proto-Europic, palatal consonants as found in other Mitian languages appear to have merged with dental ones. This is accordance with the sound correspondences proposed by Allan R. Bomhard between Proto-Nostratic and Indo-European.
'Palatal consonants' aren't 'dorsal affricates'! While I could guess at what you meant. I'm not surprised WeepingElf didn't.
Re: Paleo-European languages
Posted: Thu Oct 29, 2020 7:30 pm
by WeepingElf
zompist wrote: ↑Thu Oct 29, 2020 5:08 pm
This is regrettable computolatry. Computers are not free of the "subjective element"; they reproduce the biases of their programmers— and in a more pernicious way because people don't realize that they can be biased.
Also, doing something on a computer doesn't make it any more scientific. If the pot is cracked, no computer will ever remove that crack. Most astrologers today use computer programs to calculate horoscopes; that doesn't make astrology any less superstitious. And the ASJP folks practice
precisely the kind of etymology about which Voltaire quipped that "consonants count for little and vowels for nothing at all". No regular sound correspondences; just inspectional similarities. No way to tell actual cognates from loanwords and chance resemblances. This is not even "proper" glottochronology, which counted
cognates rather than "similarities" - and has shown not to work because it was based on false assumptions. This is the kind of pseudo-glottochronology crackpots use to "demonstrate" fanciful language relationships. Only with computers - and misused academic credentials in fields that have actually nothing to do with comparative linguistics.
Talskubilos wrote: ↑Thu Oct 29, 2020 6:08 pm
I've just found your old article:
Fair. But that is indeed an
old article, and I have
changed my opinion about this since then, and no longer assume a dental-palatal merger in Pre-PIE. It
may have happened, but it may just as well have
not. We don't know yet; probably, only comparison with external relatives could tell, but those external relatives have not been established yet. Also, you had misrepresented the palatal consonants I wrote about as "dorsal affricates" such that I could not remember writing about them because i never did.
 I looked over the graph and think I might have found a few things you all missed ....
I looked over the graph and think I might have found a few things you all missed ....