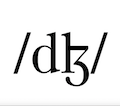Unnamed conlang v. 2:
Root-initials:
/p t tʃ k/ <p t c k>
/s ʃ h/ <s sy h>
/l ʎ/ <l ly>
/m n ɲ/ <m n ny>
Root-medials:
/p t tʃ tɬ cʎ̥˔ k/ <p t c tl cl k>
/pʰ tʰ tʃʰ kʰ/ <ph th ch tlh clh kh>
/p' t' tʃ' k'/ <p' t' c' k'>
/b d dʒ dɮ ɟʎ̞ g/ <b d j dl jl g>
/bʱ dʱ dʒʱ gʱ/ <bh dh jh gh>
/ɓ ɗ ʄ ɠ/ <b' d' j' g'>
/ᵐb ⁿd ⁿdʒ ⁿdɮ ⁿɟʎ̞ ᵑg/ <mb nd nj ndl njl ng>
/ᵐbʱ ⁿdʱ ⁿdʒʱ ᵑgʱ/ <mbh ndh njh ngh>
/ᵐɓ ⁿɗ ⁿʄ ᵑɠ/ <mb' nd' nj' ng'>
/m n ɲ/ <m n ny>
/m̥ n̥ ɲ̊/ <mh nh nhy>
/m̰ n̰ ɲ̃/ <m' n' n'y>
/f s ɬ ʃ ʎ̥˔ h/ <f s lh sy lhy h>
/s' ʃ'/ <s' s'y>
/v z l ʒ ʎ/ <v z l zy ly>
/ᵐv ⁿz ⁿl ⁿʒ ⁿʎ/ <mv nz nl nzy nly>
/l̰ ʎ̰/ <l' l'y>
Vowels:
/i u e ɔ a/ <i u e o a>
(C)V syllables
There's now explicit rules for the (very complex) system consonant mutation, which occurs both within words and across words, triggered by particular morphemes. Morphemes beginning with one of /p t tʃ k s ʃ h l ʎ/ undergo mutation according to the following 2x5 grid of consonant grades:
Code: Select all
plain voiced aspirate glottalic 1 glottalic 2
oral p t tʃ k s ʃ h l ʎ b d dʒ g z ʒ v l ʎ pʰ tʰ tʃʰ kʰ s ʃ f ɬ ʎ̥˔
p' t' tʃ' k' s' ʃ' f~∅ tɬ cʎ̥˔ p' t' tʃ' k' s' ʃ' f l̰ ʎ̰
nasal ᵐb ⁿd ⁿdʒ ᵑg ⁿz ⁿʒ ᵐv ⁿl ⁿʎ ᵐbʱ ⁿdʱ ⁿdʒʱ ᵑgʱ s ʃ f ɬ ʎ̥˔
I'm not sure if it's clear, but basically the plain/voiced nasal grades are identical and the glottal grades are identical in both nasal and oral.
Morphemes that begin with a nasal consonant or a vowel are more complicated. They fall into two classes, which undergo mutation differently:
Code: Select all
Class 1:
plain/voiced aspirate glottalic
oral/nasal m n ɲ ∅ m̥ n̥ ɲ̊ s~(ʃ)/f m̰ n̰ ɲ̃ b/d~(dʒ)/g
Class 2:
plain voiced aspirate glottalic
oral m n ɲ ∅ b d dʒ g bʱ dʱ dʒʱ gʱ ɓ ɗ ʄ ɠ
nasal ᵐb ⁿd ⁿdʒ ᵑg ᵐbʱ ⁿdʱ ⁿdʒʱ ᵑgʱ ᵐɓ ⁿɗ ⁿʄ ᵑɠ
The class 1 aspirate and glottalic grades of the zero initial vary by the triggering morpheme: some trigger the s~(ʃ) set, others the f set, etc. Among the s~(ʃ) set and d~(dʒ), /ʃ/ and /dʒ/ appear before /e a/, while /s/ and /d/ appear before other vowels.
-----
Well, I'd really like to come up with a romanization that's systematic with respect to all these consonant gradations, but honestly working all this out was tiring so I'm just gonna hope somebody else here thinks that sounds like a fun task.
-----
Ok, actually, here are some simple examples for romanization:
/pe/, def.sg.m article, glottalic 1 grade
/ʎɔ/, def.sg.f article, oral voiced grade
/pep'e/ def.pl.m article, glottalic 1 grade
/ʎɔʎɔ/, def.pl.f article, oral voiced grade
/e-/, pl. suffix, nasal plain/voiced grade, class 2
/lɔga-/, augmentative, oral aspirate grade
/la/, acc., plain grade
/taha/, "cat"
/muⁿɟʎ̞ete/, "palm frond", class 1
/ɔᵑgu/, "female panther", class 2
/nɔmɔ/, "man", class 2
/pe t'aha/, /ʎɔ daha/, /eⁿdaha/, /pep'e ɠeⁿdaha/, /ʎɔʎɔ geⁿdaha/, /lɔgatʰaha/, /pe tɬɔgatʰaha/
/pe m̰uⁿɟʎ̞ete/, /emuⁿɟʎ̞ete/, /pep'e ɠemuⁿɟʎ̞ete/, /lɔgam̥uⁿɟʎ̞ete/
/ʎɔ gɔᵑgu/, /eᵑgɔᵑgu/, /ʎɔʎɔ geᵑgɔᵑgu/, /lɔgagʱɔᵑgu/
/pe dɔmɔ/, /eⁿdɔmɔ/, /la nɔmɔ/, /lɔgadʱɔmɔ/